
The skeptic's guide to consuming AI research with a pinch of salt
Theoretically rigorous studies aren't enough if they study only a part of the picture

AI research gets shared all over LinkedIn. No matter what you believe in, there’s a credible study backing it somewhere.
You’re right to be skeptical about every new ‘AI expert’ shouting out from the rooftops on LinkedIn.
But what about peer-reviewed AI research coming out from credible labs and top universities?
As it turns out, research can be right in the narrow sense and still misleading in the larger sense.
This, of course, applies to everyone writing about AI - including anything I put out there.
This post is about making sense of AI research - looking for gaps in a theory and bridging those with complementary bodies of research.
And I’m launching something super-interesting with this post - keep scrolling through the argument to learn more.
The three types of AI research out there
While researching for Reshuffle, I looked through the research on AI and came across three types of issues in the research:
Type 1: Rigorous research but from a different era - caveated as such by the researchers themselves but over-extended by enthusiastic proponents to make claims about how it applies to AI today.
Possibly, the most glaring example is what I called out as Jevons Misunderstanding in my previous post, where Jevons Paradox is quoted without questioning where it applies and where it does not.
The ALM hypothesis is another such example which was drafted in a pre-AI era when many of the activities that machines can do today were simply impossible for machines to extend to.
Type 2: Intellectually rigorous research but yielding narrow findings that are generalized far more than they should be. In many ways, these are the most difficult to identify correctly.
Type 3: Agenda-based research - The researcher or their sponsor needs to push an agenda and uses data to make that point. These were easy to weed out right at the beginning. A lot of this research was coming out of the BigTech and frontier labs in partnership with universities.
For a start, let’s ignore studies that are driven by an agenda (Type 3). As for Type 1 research, the researchers categorically state assumptions and limitations and yet proponents extend the findings and use them to bludgeon alternate views into submission, without looking at the assumptions backing those findings.
Type 2 is the most interesting category.
Even when AI productivity studies are intellectually rigorous, they still repeatedly make four assumptions about the impact of AI on work that are no longer true.
Four assumptions that intellectually rigorous studies on AI get wrong
There are four things that Type 2 studies often get wrong. With these fundamental misframings, the studies - no matter how rigorous - reveal results that cannot easily be generalized.
1. They assume a fixed capability frontier:
A productivity study estimates an effect at time T. AI capability is non-stationary; it changes every few weeks. So a point-in-time productivity study is partly obsolete by the time it’s published. Prior tools used to be static long enough to be measured. That’s no longer true.
2. They assume that value doesn’t migrate and hence productivity gains lead to value capture at the same point as yesterday:
AI’s productivity gains are often captured not by the firm or worker adopting it but upstream by the tool provider, or by the players ‘above the algo’. So the surplus migrates out of the frame that the productivity gains study is pointed at. This is why worker-level productivity can rise with no wage capture, and why the “AI boom will show up in the statistics eventually, like the Solow paradox resolved for computers” expectation is misplaced. The gain isn’t late to arrive. It’s just accruing at a different altitude, and firm-level metrics cannot count it.
3. They treat adoption as a one-time deployment:
In previous tech shifts, you could give the tool to workers and measure the lift. But AI adoption is continuous capability absorption, with tools, workflows, and practices co-evolving, plus an ongoing ‘human-in-the-loop’ bill to be paid for verification, evaluation, and re-tuning. Deployment is continuous so before-after studies assuming one-time deployment are not even structured correctly. There is no static ‘after’ destination.
4. They assume the unit of work stays the same:
A study measures a task or a role. But foundation models cut across functional boundaries and unbundle the role into fragments that get rebundled in other roles, teams, and even organizations (e.g. a task you performed could now be performed by your customer). The study measures a certain role or a certain org, not accounting for the fact that the work has moved to an entirely different location.
Every study has its merits and limitations. In writing Chapter 4 of Reshuffle, I had to work through all these studies mapping what each got right and what they didn’t.
I am launching that today as a structured interactive map of research in this space.
Here’s a full list of links to the resources:
1. The core framework - Why AI is different from previous automation technologies and how that should be factored in while analyzing different theories on AI.
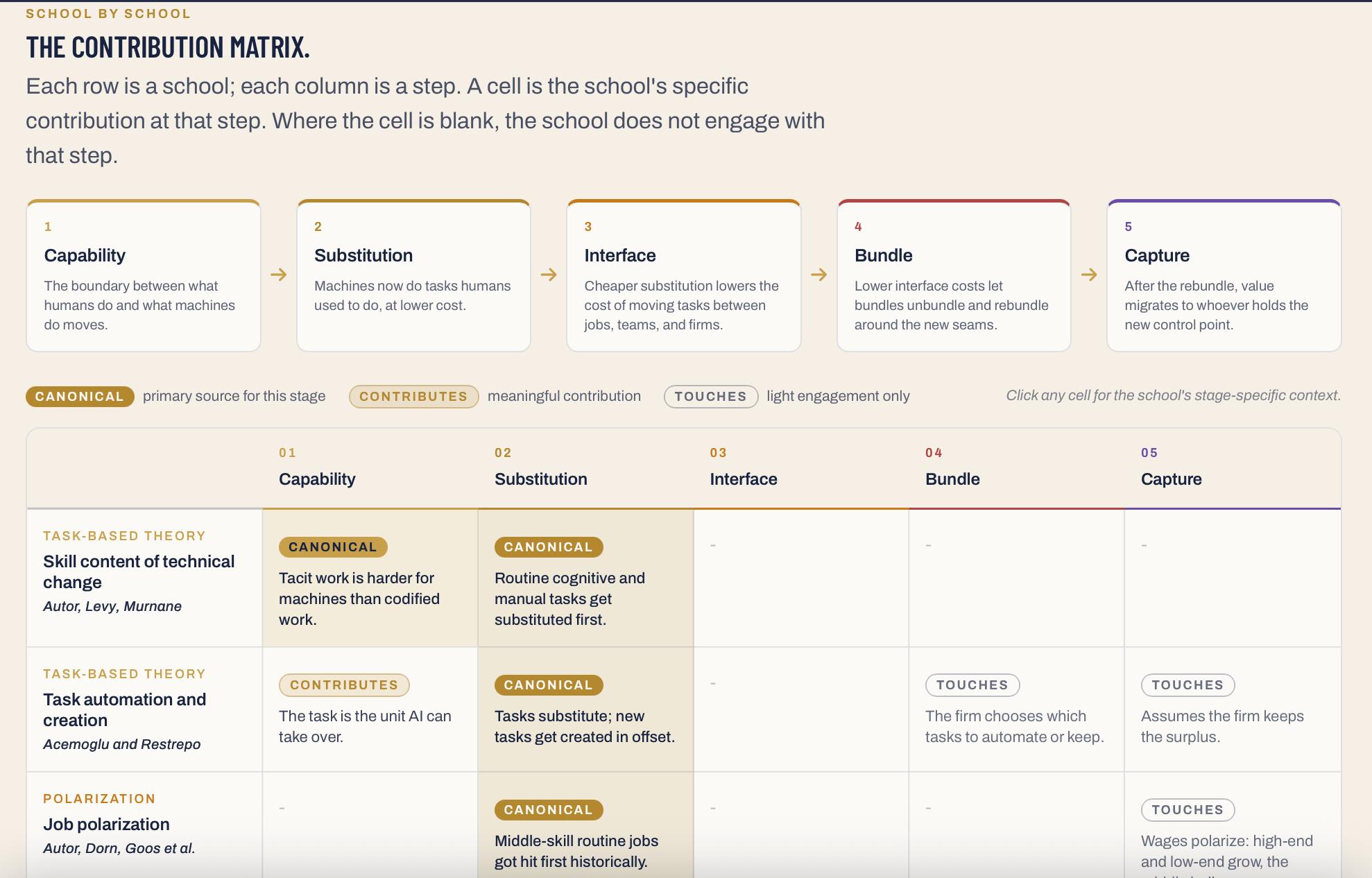
2. An interactive map of the eleven schools of thought: The index draws on eleven established research traditions, not a single point of view - this breadth is the first test of rigor.
3. What is different about AI: Tests where each theory breaks with AI and explains how to fix it.
4. The contribution matrix: Shows exactly what each school contributes and where it falls short - no theory is over-claimed and every gap is explicitly identified.
5. The false binaries: Explains why we see superficial framings - automation vs augmentation, hard vs soft skills, generalist vs specialist - and why those framings fail.
Mapping and reconciling the different schools of thought
Instead of picking a single school, I took eleven of them - across labour economics, modularity theory, value migration, the ghost-work literature, organizational design, and the political economy of work - and treated each as a partial view of one phenomenon rather than a rival account of the whole.
The wager is that each of these traditions is right about something and blind to something else. There’s a method to the blindness - it’s not random.

However, to compare these schools while accounting for the 4 problems mentioned above, these studies need to be placed on a broader causal chain.
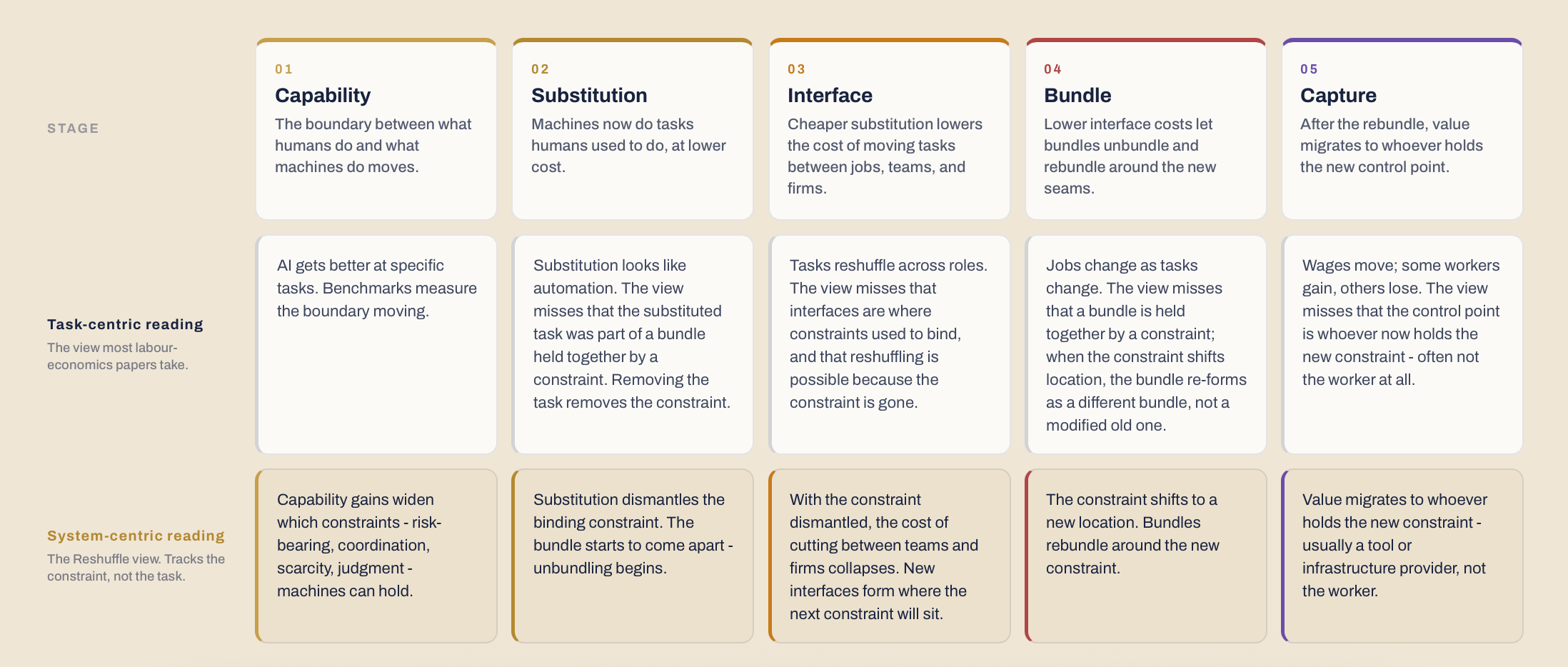
To make the different schools comparable, I map them onto a single chain: capability, substitution, interface, bundle, capture.
First, AI changes the capability frontier. It changes what machines can perceive, generate, reason about, coordinate, or execute. But because this frontier is non-stationary, the capability layer cannot be treated as a fixed input.
Second, capability change creates possibilities for substitution or augmentation. Some activities can be automated, some can be assisted, and some become cheaper, faster, or more widely available. This is the layer most productivity studies observe most directly but also the layer they stop at.
Third, substitution and augmentation change the interface structure of work. Once AI can perform parts of a tacit workflow, new boundaries appear in the workflow.
Fourth, this changes the bundle. Activities that were previously fused inside a human role can now be separated and recombined across roles, workflows, and teams - even orgs. The job, role, workflow, or organizational unit no longer has to be held together in the same way. Work can be unbundled from one role and rebundled into another. It can move from employee to customer, from firm to platform, from team to agent, from professional service to software layer, or from human execution to human verification.
Fifth, the new bundle changes capture. Value does not necessarily accrue where productivity was measured. It may migrate to the owner of the model, the owner of the interface, the owner of the workflow, the owner of distribution, the owner of trust, or the actor that controls the new point of coordination.
Where Type 2 studies go wrong
Type 2 productivity studies usually miss all this.
They often see automation vs augmentation. But they often stop before interface, bundle, and capture. As a result, they may correctly measure a local effect while missing the system-level reshuffle that determines whether the effect generalizes.
This is why a study can be rigorous and still be strategically incomplete.
It may correctly show that AI improves a worker’s productivity on a measured task. But it may not tell us whether the capability frontier will hold, whether the workflow will be redesigned, whether the task will remain inside that role, whether the surplus will accrue to the worker or firm, or whether the entire bundle will migrate to another point in the ecosystem.
The Reshuffle thesis, therefore, does not reject productivity studies. It works across them, using them as evidence at one point in a larger chain, not as a full theory of AI’s impact on jobs. They tell us what AI can do to a task under observed conditions. They do not, on their own, tell us how work will be unbundled, where value will migrate, or how jobs, firms, and ecosystems will be rebundled around the new capability frontier.
The real question
The real question is not only: what does AI do to this task?
It is:
What does AI make newly capable?
What does that substitute or augment?
What new interfaces does it create?
What work bundles does it unbundle and rebundle?
Where does value finally get captured?
Until we answer the full chain, we are not really studying the impact of AI on jobs. We are studying a local productivity effect inside a system that may already be reshuffling around it.
The Reshuffle Index - in beta
This research forms the bedrock of the Reshuffle Index, currently in beta with clients, and launching later this year to the market. The index tracks the extent to which different industries, jobs, and organization types are getting reshuffled because of AI.
The index is currently live in beta with clients, supporting their internal strategy and will be launching as a market-facing index later this year in partnership with other firms.
If you’d like to learn more about the index, just reply to this email and get in touch.
Once more - here’s the full list of links to the resources:
1. The core framework - Why AI is different from previous automation technologies and how that should be factored in while analyzing different theories on AI.
2. An interactive map of the eleven schools of thought: The index draws on eleven established research traditions, not a single point of view - this breadth is the first test of rigor.
3. What is different about AI: Tests where each theory breaks with AI and explains how to fix it.
4. The contribution matrix: Shows exactly what each school contributes and where it falls short - no theory is over-claimed and every gap is explicitly identified.
5. The false binaries: Explains why we see superficial framings - automation vs augmentation, hard vs soft skills, generalist vs specialist - and why those framings fail.
The piece is right that productivity studies measure the wrong layer, but the part it treats as the AI-era twist (value capture moving off the worker) is nothing new.
The divergence between productivity going up and who gets paid for it is as old as the industrial revolution. Codifying expertise, cutting the worker out of the customer relationship, value landing on a platform instead of a person. Whether it's the assembly line, the ATM, or Expedia, it has always happened as new tech enabled it.
The value never flowed to the raw tech provider, and I don't think that will change now. LLM architecture is probabilistic AND it's an approximation by design. It gets closer to reliable but never gets there, so anything that depends on being right needs an intermediary that wraps the model and supplies the trust. Reliable systems have always been built out of unreliable parts.
So it's the same disruption model as ever. Incumbents get first shot, usually miss, (for reasons unrelated to tech but rather how capital gets allocated) and many get replaced. The one constant is that the workers don't end up owning the value.
The only question imo is whether this version of AI meaningfully different in degree from previous waves. That's still TBD.
I feel like the insights about value migration and unit of work shifts are similarly insightful to The stack fallacy - gets to the fast assumptions we accidentally build in based on our own lived context.